Article
Introducing Vector 4: A Smarter Way to Read Model Agreement
Why raw consensus can mislead you and how weighted scoring fixes it
Published January 31, 2026•3 min read•Updated February 11, 2026

# Introducing Vector 4: A Smarter Way to Read Model Agreement
[](https://substackcdn.com/image/fetch/$s_!2Do6!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F5f667b17-55e6-4e07-a8fe-7d88cf77eac1_1920x1080.jpeg)
**Why raw consensus can mislead you and how weighted scoring fixes it**
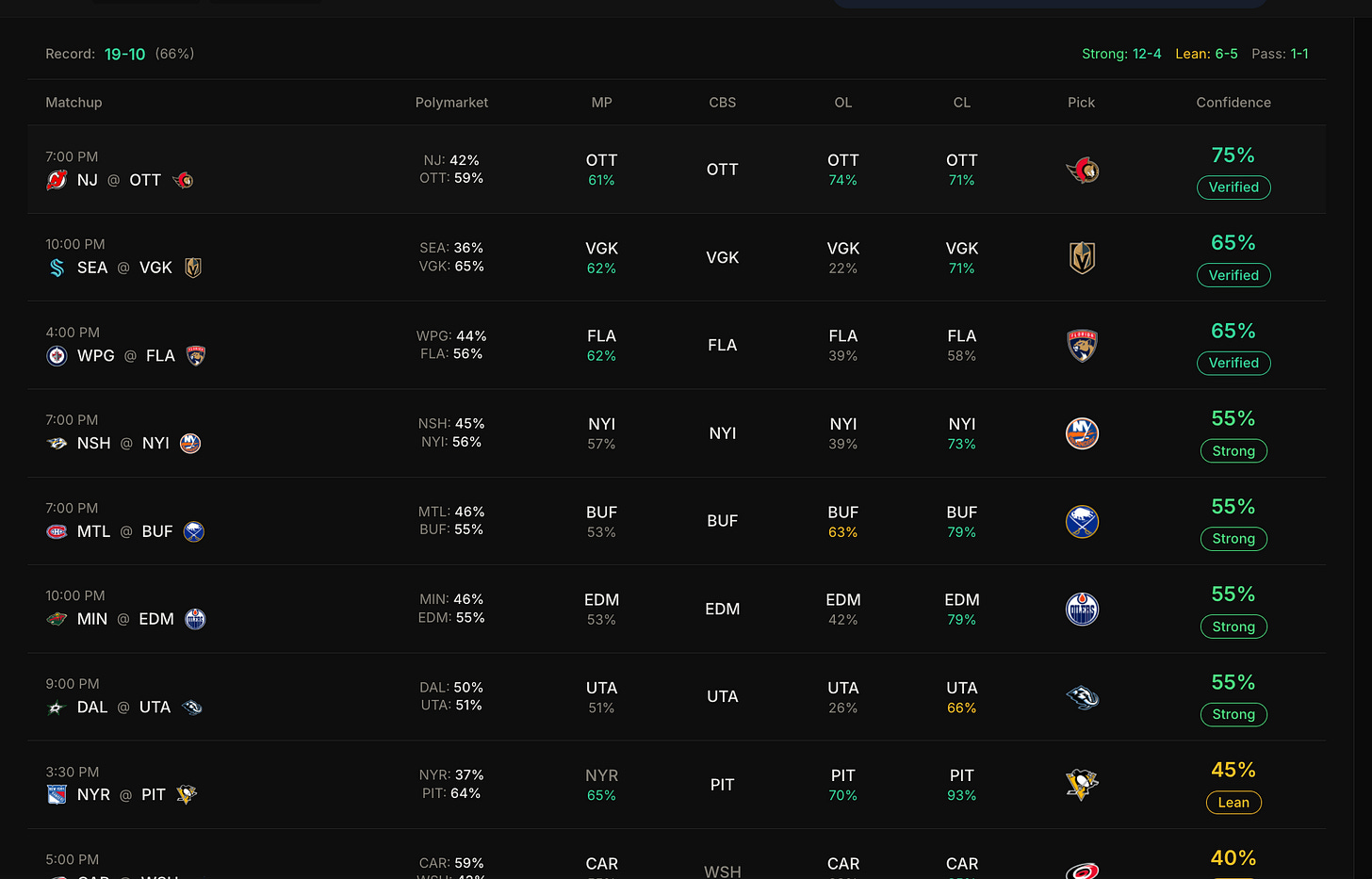
We’ve been running The Otterline’s 4-model system long enough to know that not all agreement is created equal. A 4/4 consensus where every model is barely clearing 55% confidence tells a very different story than one where MoneyPuck is at 65% and ChattyLine is pushing 80%. That’s the gap Vector 4 is designed to close.
## The Problem with Straight Consensus
Traditional consensus logic is binary: a model either picks Team A or Team B, and you count the votes. Three out of four models on the same side? That’s your play.
But this flattens critical information. Our data shows that a 3/4 surface agreement with lukewarm confidence across the board often performs worse than a 2/4 split where the agreeing models are showing high conviction. Raw consensus treats a 53% pick the same as a 73% pick Vector 4 doesn’t.
[](https://substackcdn.com/image/fetch/$s_!Tuv1!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F4c1741c5-c14b-4066-bf41-c740915e0a32_1944x1246.png)## How Vector 4 Works
Each model contributes points to their picked team based on two factors: their base weight and their confidence level.
**Base + Confidence Bonuses:**
- **MP:** 2.0 base, with +1.0 bonus when confidence hits 60-69%
- **CBS:** 1.5 points flat
- **Otterline AI:** 1.0 base, +1.0 at 70%, +1.5 at 80%+
- **ChattyLine:** 1.0 base, +1.0 at 70%, +1.5 at 80%+
The team with the higher combined score wins the pick. More importantly, the *magnitude* of that score determines the confidence tier.
## The Tier System
Vector 4 outputs five distinct buckets, each trackable for long-term accuracy:
- **Elite (8.5+ points):** Maximum conviction—this is rare and requires multiple high-confidence models stacking
- **Verified (6.5-8.4 points):** Strong alignment with meaningful confidence behind it
- **Strong (5.0-6.4 points):** Solid signals worth standard unit sizing
- **Lean (3.5-4.9 points):** Playable but with reduced exposure
- **Split (<3.5 points):** Models are genuinely divided—stay away or fade
## Why This Matters for Bankroll Management
Here’s where it gets practical. Under straight consensus, you might see a 3/4 pick and default to a 1-unit bet. But Vector 4 reveals the actual conviction behind that agreement.
That “strong” 3/4 consensus with soft confidence numbers? It might score out as a Lean suggesting 0.5 units is the appropriate sizing. Meanwhile, a game where only two models agree but both are showing 75%+ confidence could score into Strong territory, warranting full unit exposure.
This granularity is something we’ve wanted to implement since we started tracking model-by-model confidence data. Now we have enough historical performance across buckets to trust the system.
## Early Results
We’re currently running Vector 4 in parallel with our standard consensus display you’ll find it positioned near the bottom of the consensus page. The 19-10 record (66%) you’re seeing includes Strong picks running at 12-4 and Lean at 6-5, which aligns with exactly what the tiers are designed to predict: Strong should hit more often than Lean.
We’re keeping it below the fold until we’ve accumulated enough data across all buckets to call it battle-tested. But the logic is sound, the early returns are encouraging, and the per-bucket tracking gives us transparency we didn’t have before.
## The Bottom Line
Vector 4 isn’t replacing consensus it’s giving you the *quality* of that consensus. When four models agree and the score hits Diamond, you know you’re looking at genuine convergence. When three models agree but the score lands in Lean territory, you know the surface agreement is masking uncertainty underneath.
Better information, better sizing, better tracking. That’s the goal.
*Check it out on the consensus page and let us know what you think.*